はじめに──“指数リバランス” が狙い目である3つの理由
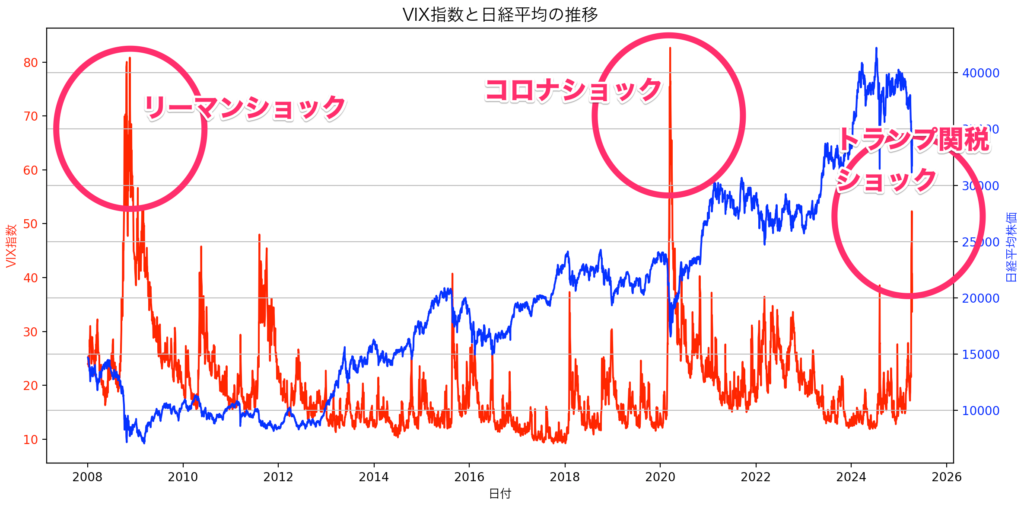
株式投資の世界では「業績相場」「金融相場」「テーマ株」とさまざまな短期ドライバーが語られますが、最も需給が読みやすいイベントは何かと問われれば、インデックスの定期入れ替えが真っ先に挙がります。日経平均(Nikkei 225)の場合、毎年 9〜10 月に構成銘柄の見直しが行われ、発表から採用日までの間にファンド買い/売りが機械的に発生します。以下の3点が、投資家にとって極めて狙いやすい理由です。
- 毎年ほぼ同じカレンダーで発生 … 予測が立てやすく、検証もしやすい
- 連動 ETF の需給インパクトが巨大 … 採用銘柄に即日で数百億円の買い
- 情報が完全に公開される … インサイダー要素が少なく個人が戦いやすい
一方で「実際にどのウインドウが最もパフォーマンスが高いのか」は、過去データを検証しなければ分かりません。本記事では発表30営業日前に仕込み→採用60営業日後まで保有というシンプルなルールを例に、Python でバックテストする方法を解説し、さらに応用アイデアまで網羅します。
この記事で得られるもの
- 日経平均リバランスを自動で検証できるサンプルスクリプト(コピペで動く)
- コードの全ロジックを 関数単位で分解 した日本語ドキュメント
- 先回り・ギャップ・フォローの3ウインドウ戦略を平均リターンとαで評価
- 除外銘柄逆張り/候補銘柄スクリーナーなど5つの応用アイデア
- 学習ロードマップ
サンプルスクリプト全文(コピペで動作)
"""
Nikkei225 定期入れ替えイベント先回りバックテスト
──────────────────────────────────────────────
* 発表30営業日前 → 採用60営業日後までを検証
"""
# ── 1. ライブラリ ────────────────────────────
from datetime import timedelta
from typing import List
import pandas as pd
import yfinance as yf
import matplotlib.pyplot as plt
import numbers
# ── 2. EVENTS を列挙 (announce, effective, action, code) ─
EVENTS = [
("2025-03-11", "2025-04-01", "ADD", "6532.T"), # ベイカレント
("2025-03-11", "2025-04-01", "REMOVE", "9301.T"), # 三菱倉庫
("2024-09-04", "2024-10-01", "ADD", "4307.T"), # 野村総研
("2024-09-04", "2024-10-01", "ADD", "7453.T"), # 良品計画
("2024-09-04", "2024-10-01", "REMOVE", "3863.T"), # 日本製紙
("2024-09-04", "2024-10-01", "REMOVE", "4631.T"), # DIC
]
# ── 3. ユーティリティ ─────────────────────────
def _scalar(val) -> float:
if isinstance(val, numbers.Number):
return float(val)
if isinstance(val, (pd.Series, pd.DataFrame)):
return float(val.squeeze())
return float(val[0])
def _parse_events(raw) -> pd.DataFrame:
df = pd.DataFrame(raw, columns=["announce", "effective", "action", "code"])
df["announce"] = pd.to_datetime(df["announce"], format="%Y-%m-%d")
df["effective"] = pd.to_datetime(df["effective"], format="%Y-%m-%d")
return df
def _fetch_price(ticker: str, start, end) -> pd.Series:
df = yf.download(ticker, start=start, end=end, progress=False)
col = "Adj Close" if "Adj Close" in df.columns else "Close"
s = df[col].copy(); s.name = "close"
return s.asfreq("B")
# ── 4. メイン ────────────────────────────────
def main() -> None:
ev = _parse_events(EVENTS)
start_pad = ev["announce"].min() - timedelta(days=60)
end_pad = ev["effective"].max() + timedelta(days=90)
bench = _fetch_price("^N225", start_pad, end_pad)
PRE, POST = 30, 60
recs: List[dict] = []
for row in ev.itertuples(index=False):
px = _fetch_price(
row.code,
row.announce - timedelta(days=PRE * 2),
row.effective + timedelta(days=POST * 2),
)
idx_ann = px.index.get_loc(row.announce, method="nearest")
idx_eff = px.index.get_loc(row.effective, method="nearest")
pre = (_scalar(px.iloc[idx_ann - 1]) /
_scalar(px.iloc[max(idx_ann - PRE, 0)]) - 1) * 100
gap = (_scalar(px.iloc[idx_eff - 1]) /
_scalar(px.iloc[idx_ann]) - 1) * 100
post = (_scalar(px.iloc[min(idx_eff + POST, len(px) - 1)]) /
_scalar(px.iloc[idx_eff]) - 1) * 100
bench_pre = (_scalar(bench.loc[px.index[idx_ann - 1]]) /
_scalar(bench.loc[px.index[max(idx_ann - PRE, 0)]]) - 1) * 100
bench_post = (_scalar(bench.loc[px.index[min(idx_eff + POST, len(px) - 1)]]) /
_scalar(bench.loc[px.index[idx_eff]]) - 1) * 100
recs.append({
"code": row.code, "action": row.action,
"announce": row.announce.date(), "effective": row.effective.date(),
"pre_ret_%": round(pre, 2),
"gap_ret_%": round(gap, 2),
"post_ret_%": round(post, 2),
"alpha_pre_%": round(pre - bench_pre, 2),
"alpha_post_%": round(post - bench_post, 2),
})
df = pd.DataFrame(recs)
print("=== 個別リターン ===\n", df.to_string(index=False))
summary = (df.groupby("action")[[
"pre_ret_%", "gap_ret_%", "post_ret_%",
"alpha_pre_%", "alpha_post_%"
]].mean().round(2))
print("\n=== 平均リターン (%) ===\n", summary)
cols = [c for c in ("pre_ret_%","gap_ret_%","post_ret_%") if c in summary.columns]
if cols:
summary[cols].T.plot(kind="bar", figsize=(8,4),
title="Average Return by Window (ADD vs REMOVE)")
plt.ylabel("%"); plt.tight_layout(); plt.show()
else:
print("⚠ グラフ対象列が無く、描画をスキップしました。")
if __name__ == "__main__":
main()</code></pre>
スクリプトを“分解”して理解する
§1 EVENTS リスト ― 履歴入力の窓口
最小構成では 4 列(発表日・採用日・アクション・ティッカー)をタプルで並べるだけ。過去 10 年分をまとめればそのまま長期バックテストへ拡張できます。
§2 _fetch_price() ― 株価データ取得
- yfinance API で
Adj Close優先 ⇒ 調整後終値 - 営業日頻度にリサンプリングして休日欠損を吸収
s.name = "close"で列名付与(rename() 削除)
§3 _scalar() ― DataFrame/Series → float へ統一
yfinance はティッカーを配列で返す場合があるため、どんな型でも必ず 安全にスカラー化 し、列型を float に固定。これで groupby.mean() が object 型になる事故を回避します。
§4 メインループ ― 3 ウインドウ計算
| 変数 | 計算式 | 意味 |
|---|---|---|
| pre | (発表−1) ÷ (発表−30) | 先回りリターン |
| gap | (採用−1) ÷ (発表当日) | 思惑リターン |
| post | (採用+60) ÷ (採用当日) | フォローリターン |
同ウインドウの ^N225 リターンを差し引き、α=純粋なイベント効果 を算出します。
応用アイデア:日経平均採用・除外イベント投資
1. 発表リーク検出アルゴリズム
直近 20 日平均出来高の 5 倍を超えたプライム銘柄を抽出し、過去 3 年の入れ替え銘柄と重複チェック。確度ランキングを作り早期仕込み。
2. 採用当日寄り付き逆張り
採用銘柄は寄り付きギャップアップ後に押し目を形成しやすい。発表当日終値を上回る寄り付き幅が +5 %以上なら、引け成りで空売り→翌日引け買い戻し。
3. 除外銘柄のカバードコール
発表日直後は IV (Implied Volatility) が急騰するため、除外銘柄に ATM コールを売ると時間価値で優位性が出る。
4. 採用候補“EPS 成長 × 流動性”フィルタ
日経平均はセクター/流動性バランスを重視する。5 年 EPS CAGR 上位 10 % & 売買代金上位 20 % を条件にし、PBR 1.5 倍以下を割り引いて候補を抽出。
5. 除外→TOPIX 需給アービトラージ
日経平均から外れても TOPIX 構成は維持される。TOPIX 先物ロング+除外銘柄ショートで中立ポジションを構築、需給ギャップ解消で利ざやを稼ぐ。
リスクと注意点
- ファンドのリバランス方法が年々変わる … メカニカル買いが分散し、シグナルが薄まる可能性
- 信用規制・貸借銘柄指定解除 … 除外銘柄が空売り禁止になると戦略が機能しない
- ティッカー統合・株式併合 … 過去データ取得で指数リターンに歪みが生じる
まとめ──自分のロジックで検証できれば“期待値”が見える
市場で語られるイベント投資の多くは断片的な成功体験に基づくものですが、Python でバックテストすれば「平均すると本当に勝てるか」を客観的に判断できます。ぜひ本スクリプトをベースに、ウインドウやロジックを自由に改変し、自分だけの優位性を発掘してください。
Pythonを学ぶなら「Udemy」で効率的に
独学でPythonを学ぶ場合、公式リファレンスだけでは挫折しがちです。
そんな時に心強いのが、動画で体系的に学べるUdemyの講座。
- Python初心者向け講座から、投資データ分析に特化した実践講座まで多数
- 買い切り型で、一度買えばいつでも復習可能
- セール時は90%オフなど、非常にお得
投資家にとっての“自己投資”として、Udemyは非常にコスパの高い選択肢です。
【裏ワザ】Udemyの講座は“ある方法”でさらにお得に買える
実は、Udemyの講座はポイントサイトを経由することで、さらにお得に購入できることをご存知ですか?
おすすめは「ハピタス」というポイントサイト。
ハピタスを経由してUdemyで講座を購入すると、購入金額の数15%がポイントとして還元されます(2025年4月調査時点)。
手順は3ステップ
- ハピタスに無料登録
- 「Udemy」と検索して表示されたリンクをクリック
- 講座を通常通り購入するだけ

講座はPythonの基本から株価分析、AI株価予測まで、いろいろそろっています。

学びながらポイントも貯まり、一石二鳥です。